
Loadshape clustering from AMI data
How to generate loadshape clusters from AMI data.
Daily loadshape identification is a common problem in utility data analysis. Before the advent of AMI metering, end-use metering surveys and simulation were often used to develop diurnal loadshapes for different seasons and weekday types. These surveys usually involved relative modest numbers of customers, whose customer class was usually well-known, and the loadshapes were often one of primary deliverables. Consequently generating the range of loadshapes observed in the surveys was not typically a problem for utility analysts.
With the advent of automated metering infrastructure (AMI), the volume of data increased significantly. Unfortunately, the analysis methods used for the end-use load surveys are not always helpful because the AMI data is not labeled. To address this problem, unsupervised machine learning methods can be used to identify the principal loadshapes found in the AMI data.
This post describes the methodology use by the OpenFIDO loadshape pipeline. The use-case presented here is based on a data set from a utility containing 1 year of AMI data from 2015 for 973 customers. The original dataset has been sanitized to preserve privacy and reduce the size of the data repository. In addition the subhourly data has been rolled up to hourly data.
The methodology used to create the loadshape data is based on an unsupervised learning algorithm known as k-means clustering which looks for $k$ loadshapes in the data. This method partitions $N$ observations into $k$ clusters in which each observation belongs to the cluster with the nearest mean. Each cluster mean serves as a prototype of the cluster. This partition produces a data space divided into so-called “Voronoi” cells. The clusters minimize the loadshape variances (i.e., the Euclidean distances).
The analysis performed here applies the loadshape clustering method step by step, visualizing the intermediate results for inspection, and comparing the final result with an alternate t-distributed stochastic neighbor embedded ($t$-SNE) partitioning method. The $t$-SNE algorithm is a dimensionality reduction method that can be used to visualize high-dimensional data as a two or three-dimensional map that does not share any common elements with the $k$-means method being validated.
The entire process is divided into seven steps, briefly summarized as follows:
-
Load the AMI data - The original data was downloaded from a utility AMI system and stored in a CSV file. This file was cleaned of identifiable information and aggregated to hourly interval energy values before being stored for analysis.
-
Identify hour types - The hours of the year are grouped into a total of 192 hour types for each season, day type, and hour that comprise the loadshapes to be found in the data.
-
Aggregate hour types - The hourly meter data is aggregated by hour type to find the mean value for each meter during each hour type.
-
Cluster the meters - The meters are clustered using $k$-means into $K$ loadshapes and each meter is assigned to the loadshape with the smallest mean-squared difference.
-
Rescale the loadshapes - Each meter is assigned a loadshape scale and offset to ensure that the loadshape has the same variance as the meter which is assigned to it.
-
Generate the loadshape weights - Each loadshape is assigned a weight based on the fraction of the total annual energy associated with that loadshape.
-
Validate the results - The results are validated using a $t$-SNE partition method.
Load the AMI data
The first task is to load the AMI data from the sanitized AMI data repository. In this case we are only interested in the timestamps with timezones, the meter ids, and the power values. All other data in the repository is ignored.
import pandas as pd
import datetime as dt
pd.set_option("max_columns",11)
pd.set_option("max_rows",9)
data = pd.read_csv("ami.csv.gz",
converters = {
"timestamp" : dt.datetime.fromisoformat,
"meter_id" : int,
"tz" : int,
"power" : float,
})
data
| meter_id | timestamp | tz | power | |
|---|---|---|---|---|
| 0 | 1 | 2015-01-01 09:00:00 | -8 | 6.31 |
| 1 | 1 | 2015-01-01 10:00:00 | -8 | 4.48 |
| 2 | 1 | 2015-01-01 11:00:00 | -8 | 5.88 |
| 3 | 1 | 2015-01-01 12:00:00 | -8 | 6.52 |
| ... | ... | ... | ... | ... |
| 8904095 | 973 | 2016-01-02 05:00:00 | -8 | 5.61 |
| 8904096 | 973 | 2016-01-02 06:00:00 | -8 | 5.39 |
| 8904097 | 973 | 2016-01-02 07:00:00 | -8 | 6.08 |
| 8904098 | 973 | 2016-01-02 08:00:00 | -8 | 5.30 |
8904099 rows × 4 columns
The data set contains nearly 9 million records, with meter id, timestamps, timezone, and power measurements. The timestamps are provided in UTC and the timezone provides the offset of the local time from the UTC timestamp. These will be necessary to determine time-dependent information such as the season, day of week, and local hour of day.
Identify hour types
The timestamps are then analysed to identify the hour types that are used to generate the loadshapes. The hour type is based on the season (winter=0, spring=1, summer=2, and fall=3) and the day type (weekday=0 and weekend=1). These, along with the 24 hours of the day, result in 192 hour types, which are associated with each meter observation.
hour = (data["timestamp"].apply(lambda x:x.hour-1)+data["tz"]).astype(int).mod(24)
weekend = data["timestamp"].apply(lambda x:(int(x.weekday()/5)))
season = data["timestamp"].apply(lambda x:x.quarter-1)
data["hourtype"] = season*48 + weekend*24 + hour
data
| meter_id | timestamp | tz | power | hourtype | |
|---|---|---|---|---|---|
| 0 | 1 | 2015-01-01 09:00:00 | -8 | 6.31 | 0 |
| 1 | 1 | 2015-01-01 10:00:00 | -8 | 4.48 | 1 |
| 2 | 1 | 2015-01-01 11:00:00 | -8 | 5.88 | 2 |
| 3 | 1 | 2015-01-01 12:00:00 | -8 | 6.52 | 3 |
| ... | ... | ... | ... | ... | ... |
| 8904095 | 973 | 2016-01-02 05:00:00 | -8 | 5.61 | 44 |
| 8904096 | 973 | 2016-01-02 06:00:00 | -8 | 5.39 | 45 |
| 8904097 | 973 | 2016-01-02 07:00:00 | -8 | 6.08 | 46 |
| 8904098 | 973 | 2016-01-02 08:00:00 | -8 | 5.30 | 47 |
8904099 rows × 5 columns
Aggregate hour types
The next task is to calculate the average load for each hour type of each meter. The result is then pivoted to create one column for each hour type and one row for each meter.
groups = data.groupby(["meter_id","hourtype"]).mean().reset_index()
groups = groups.pivot(index="meter_id",columns="hourtype",values="power")
groups.fillna(method="ffill",inplace=True)
groups
| hourtype | 0 | 1 | 2 | 3 | 4 | ... | 187 | 188 | 189 | 190 | 191 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| meter_id | |||||||||||
| 1 | 5.737077 | 5.319385 | 4.922769 | 4.934000 | 4.465538 | ... | 7.204231 | 7.076154 | 6.870385 | 6.311154 | 5.900769 |
| 2 | 0.549077 | 0.547538 | 0.547231 | 0.548154 | 0.546923 | ... | 0.693462 | 0.690000 | 0.686538 | 0.684231 | 0.683462 |
| 3 | 2.947692 | 2.996923 | 2.886154 | 2.873846 | 3.926154 | ... | 10.800000 | 10.476923 | 6.923077 | 3.107692 | 2.538462 |
| 4 | 31.214615 | 31.007846 | 32.279231 | 32.323846 | 38.841538 | ... | 48.923462 | 45.794615 | 41.991538 | 38.596538 | 36.475000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 970 | 8.640615 | 7.935385 | 7.638000 | 7.110000 | 7.212154 | ... | 14.208077 | 13.861923 | 12.586923 | 11.545769 | 10.458077 |
| 971 | 10.575231 | 9.265846 | 7.694308 | 7.691077 | 8.035385 | ... | 13.876538 | 13.421538 | 14.191923 | 13.007308 | 11.916154 |
| 972 | 0.369385 | 0.370308 | 0.369692 | 0.367385 | 0.362308 | ... | 0.437308 | 0.435769 | 0.436154 | 0.435769 | 0.430000 |
| 973 | 12.342769 | 12.147077 | 10.622462 | 8.666462 | 8.354923 | ... | 10.270000 | 10.162692 | 9.937692 | 9.845769 | 9.771538 |
973 rows × 192 columns
Note that some meters may not have sufficient data to generate loads shapes. The following identifies which meters do not have loadshapes associated with them.
missing = data.iloc[list(set(data["meter_id"].unique()).difference(set(groups.index.values)))]
#missing.to_csv("missing.csv")
list(missing["meter_id"].unique())
[]
We can visualize the average load for each meter by hour type, where hours 0-23 are winter weekdays, hours 24-47 are winter weekends, hours 48-71 are spring weekdays, etc.
groups.T.plot(figsize=(15,8), legend=False, color='blue', alpha=0.05,grid=True,xlim=[0,191],xticks=range(0,192,24));
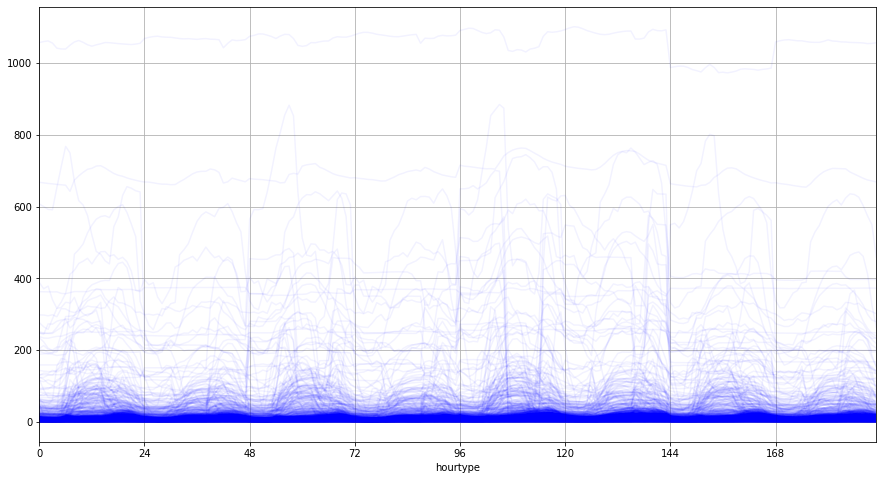
Clustering the meters
The next task is to find the clusters that partition this dataset among loadshapes with minimal Euclidean distances to the cluster centroid. We use the $k$-means algorithm to identify 10 clusters on the normalized hour type profiles and search for the smallest number of clusters necessary to ensure every group has more than 1 loadshape in it.
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
rescaled = MinMaxScaler().fit_transform(groups.values.copy())
ok = False
n_clusters = 10
while not ok and n_clusters > 1:
n_clusters -= 1
groups = data.groupby(["meter_id","hourtype"]).mean().reset_index()
groups = groups.pivot(index="meter_id",columns="hourtype",values="power")
groups.fillna(method="ffill",inplace=True)
kmeans = KMeans(n_clusters=n_clusters)
group_found = kmeans.fit_predict(rescaled)
group_data = pd.Series(group_found, name="loadshape")
groups.set_index(group_data, append=True, inplace=True)
ok = True
for group in groups.index.get_level_values(level=1).unique():
if len(groups.xs(group, level=1)) == 1:
ok = False
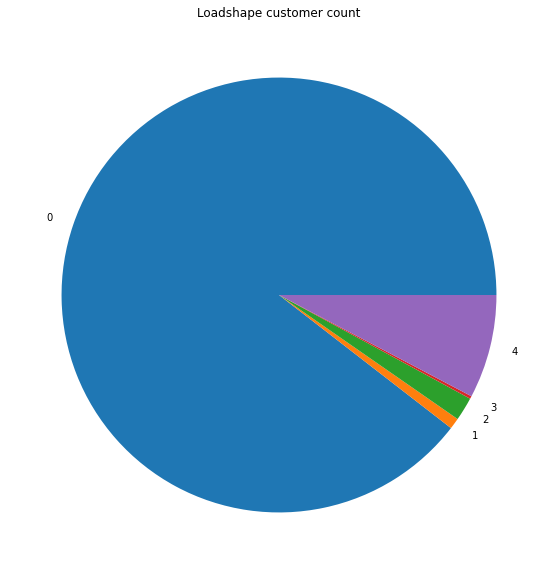
A histogram of the loadshapes found shows that only a few loadshapes are common and the remaining ones are idiosyncratic.
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
ax = groups.reset_index().groupby("loadshape")["meter_id"].count().plot.pie()
ax.set_title("Loadshape customer count")
ax.set_ylabel("");
The loadshape data is obtained by aggregating the median load and relabeling the columns to improve readability.
loadshapes = groups.groupby("loadshape").mean()
seasons = ["win","spr","sum","fal"]
weekdays = ["wd","we"]
loadshapes.columns = [f"{seasons[season]}_{weekdays[weekend]}_{hour}h" for season in range(4) for weekend in range(2) for hour in range(24)]
loadshapes
| win_wd_0h | win_wd_1h | win_wd_2h | win_wd_3h | win_wd_4h | ... | fal_we_19h | fal_we_20h | fal_we_21h | fal_we_22h | fal_we_23h | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| loadshape | |||||||||||
| 0 | 7.518608 | 6.831472 | 6.463544 | 6.296450 | 6.407418 | ... | 13.502548 | 13.197431 | 12.505875 | 11.486388 | 10.157408 |
| 1 | 334.999769 | 329.453596 | 331.760750 | 330.994173 | 342.655173 | ... | 384.495144 | 373.887308 | 356.455865 | 333.860000 | 312.682019 |
| 2 | 135.139937 | 133.300208 | 129.952633 | 130.317991 | 133.486226 | ... | 199.509276 | 193.379548 | 185.591290 | 172.179457 | 160.572534 |
| 3 | 862.073077 | 862.615385 | 862.716923 | 859.179231 | 851.286923 | ... | 870.253846 | 867.132692 | 863.890385 | 862.736538 | 862.396154 |
| 4 | 42.580202 | 40.047221 | 39.161096 | 38.817104 | 40.577592 | ... | 68.477997 | 64.067743 | 59.361592 | 53.568761 | 48.451841 |
5 rows × 192 columns
The final results are plotted with the original data to visualize how the loadshapes are representative of each cluster.
rows = int(loadshapes.shape[0]/2+0.5)
fig,ax = plt.subplots(rows,2, figsize=(18,5*rows))
for group in groups.index.get_level_values(level=1).unique():
subset = groups.xs(group, level=1)
ax = plt.subplot(rows,2,group+1)
plt.plot(subset.T,alpha=0.05,ls='-',color="blue")
plt.plot(subset.median(), alpha=1.0, ls='-',color="black")
ax.set_title(f"Loadshape {group} (N={len(subset)})")
ax.set_ylabel('Power [kW]')
ax.set_xlabel('\nHour type')
ax.grid()
y0 = ax.get_ylim()[0]
for s in range(4):
for w in range(2):
label = plt.text(s*48+w*24+12,y0,["Weekday","Weekend"][w],axes=ax)
label.set_ha("center")
label.set_va("top")
label = plt.text(s*48+24,y0,["\nWinter","\nSpring","\nSummer","\nFall"][s],axes=ax)
label.set_ha("center")
label.set_va("top")
plt.xticks(range(0,192,24),[],axes=ax)
plt.xlim([0,191])
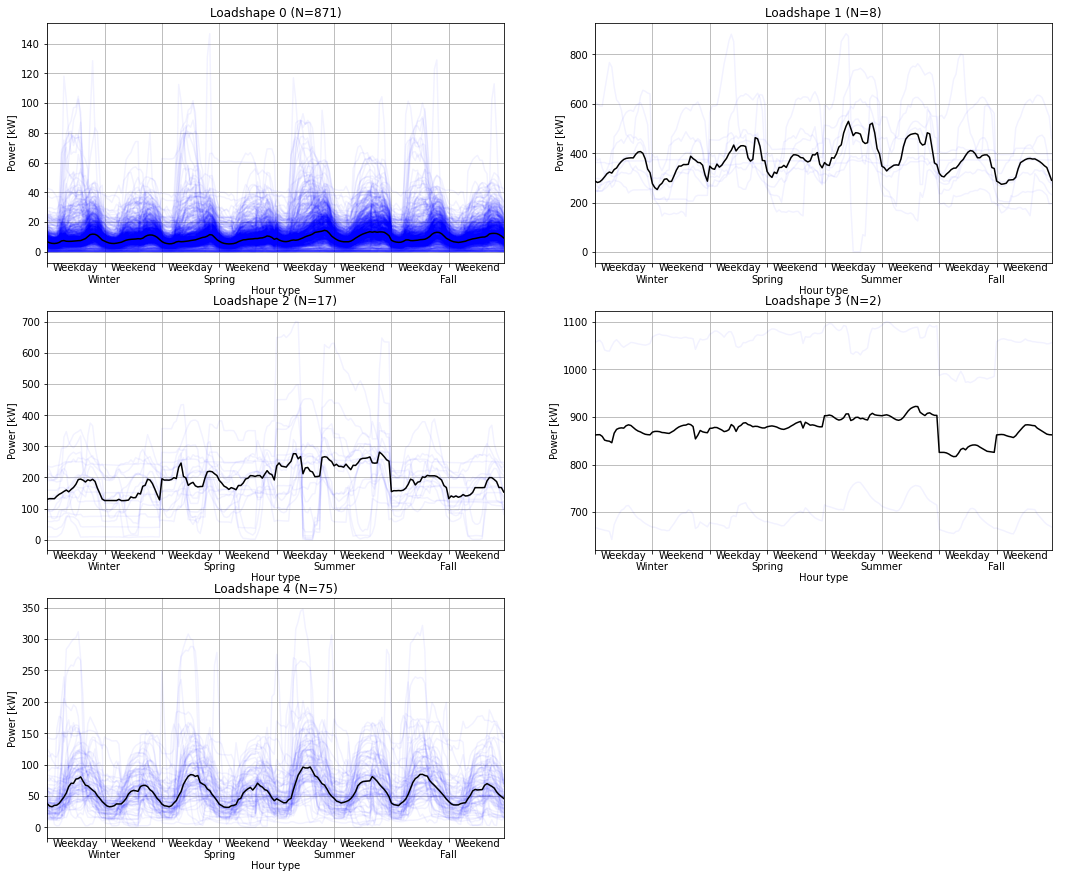
Rescaling the loadshapes
When the identified loadshapes are used to generate a load model, the mean loadshape power (as well as the total energy) will always match the original meters’ means and total energy because the methodology uses the mean power to identify the cluster centroids. However, the methodology does not address the different variances among the meters and these will not match the loadshapes centroids’ variances.
To address this, we compute the standard deviation for each meter power reading and its corresponding loadshape value.
values = groups.reset_index().set_index(["meter_id","loadshape"]).melt(ignore_index=False).reset_index().set_index(["meter_id","loadshape","hourtype"])
meters = data.drop(["tz","timestamp"],axis=1).set_index(["meter_id","hourtype"])
mapping = meters.join(values)
mapping.groupby("meter_id").std()
| power | value | |
|---|---|---|
| meter_id | ||
| 1 | 1.582521 | 1.127028 |
| 2 | 0.076137 | 0.071638 |
| 3 | 4.697922 | 4.305768 |
| 4 | 7.073779 | 5.767524 |
| ... | ... | ... |
| 970 | 3.891709 | 3.231951 |
| 971 | 3.088949 | 2.161910 |
| 972 | 0.056724 | 0.025850 |
| 973 | 5.555886 | 3.713034 |
973 rows × 2 columns
To rescale the loadshape so that each meter’s loadshape has the same variance we use a linear function for each meter $m$
\[y_{m,t} = scale_m x[h_{t}] + offset_m\]where the scale $scale_m = { \sigma^2_m \over \sigma^2_l}$ with $\sigma^2_m$ is the variance of the meter data and $\sigma^2_l$ is the variance corresponding loadshape data, and $offset_m = (1-scale_m)~\mu_m$ with $\mu_m$ being the mean of the meter data.
The histograms of the scales and offsets verifies the reasonableness of the range of values found.
fig,ax = plt.subplots(1,2,figsize=(18,5))
scale = pd.DataFrame(mapping.groupby("meter_id").std().power/mapping.groupby("meter_id").std().value,columns=["scale"])
scale.hist(figsize=(10,5),density=True,ax=ax[0]);
offset = pd.DataFrame((1-scale).scale*mapping.groupby("meter_id").mean()["power"],columns=["offset"])
offset.hist(figsize=(10,5),density=True,ax=ax[1]);
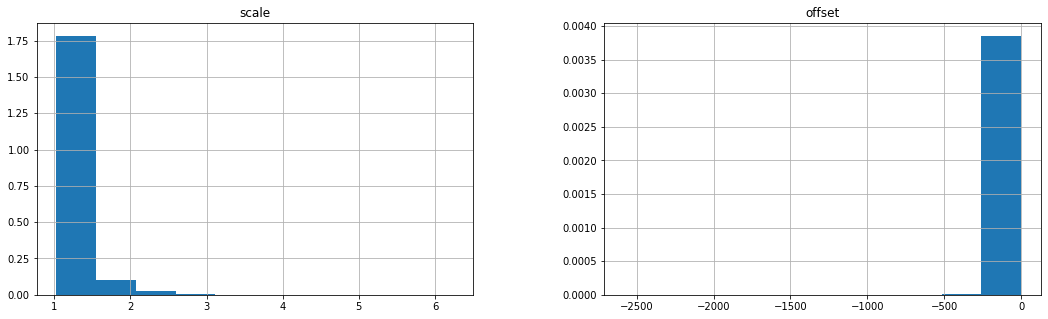
The scales and offsets are now joined with the original meter data to compute the rescaled values.
mapping = mapping.join(scale)
mapping = mapping.join(offset)
mapping["rescaled"] = mapping.value*mapping.scale + mapping.offset
mapping
| power | value | scale | offset | rescaled | |||
|---|---|---|---|---|---|---|---|
| meter_id | hourtype | loadshape | |||||
| 1 | 0 | 0 | 6.31 | 5.737077 | 1.404154 | -2.264103 | 5.791635 |
| 0 | 8.52 | 5.737077 | 1.404154 | -2.264103 | 5.791635 | ||
| 0 | 6.22 | 5.737077 | 1.404154 | -2.264103 | 5.791635 | ||
| 0 | 6.07 | 5.737077 | 1.404154 | -2.264103 | 5.791635 | ||
| ... | ... | ... | ... | ... | ... | ... | ... |
| 973 | 191 | 0 | 14.57 | 9.771538 | 1.496319 | -6.557975 | 8.063369 |
| 0 | 5.88 | 9.771538 | 1.496319 | -6.557975 | 8.063369 | ||
| 0 | 7.76 | 9.771538 | 1.496319 | -6.557975 | 8.063369 | ||
| 0 | 6.66 | 9.771538 | 1.496319 | -6.557975 | 8.063369 |
8904099 rows × 5 columns
The final rescaled loadshape values have the same variance, mean power, and total energy use as the original AMI meter data:
final=mapping.drop(["scale","offset","value"],axis=1)
pd.DataFrame(list(map(lambda x:(x.power-x.rescaled)*(x.power-x.rescaled).max(),[final.std(),final.mean(),final.sum()])),index=["std","mean","sum"],columns=["MaxSE"]).T
| std | mean | sum | |
|---|---|---|---|
| MaxSE | 2.764673e-25 | 2.051925e-22 | 1.626241e-08 |
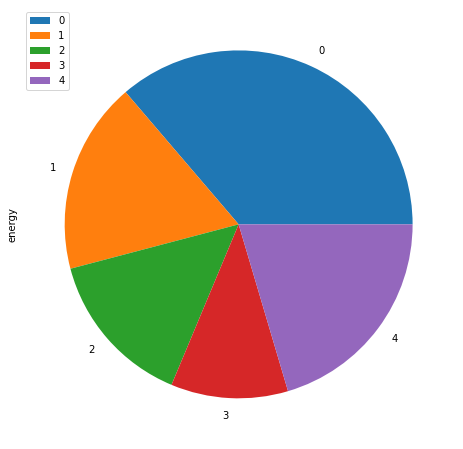
Generate the loadshape weights
The loadshape weights can be generated by computing the total energy in each loadshape meter group and dividing it by the total energy over all loadshapes.
loadshapes = groups.drop(range(192),axis=1)
total = data.drop("tz",axis=1).set_index(["meter_id","hourtype"]).join(loadshapes).groupby("loadshape").sum()
total.columns = ["energy"]
(total/total.sum()).plot.pie(y="energy",figsize=(8,8),normalize=True);
(total/total.sum()).round(3).T
| loadshape | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| energy | 0.363 | 0.178 | 0.146 | 0.109 | 0.204 |
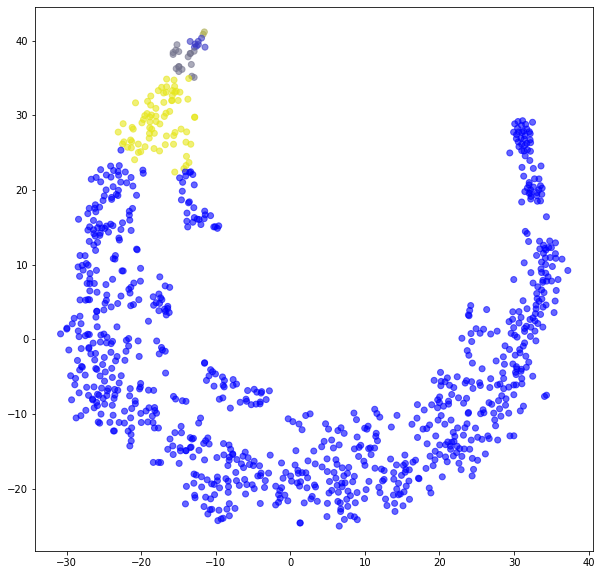
Validation
The final result is validated using a $t$-distributed stochastic neighbor embedding ($t$-SNE) algorithm to reduce the dimensionality of the original data set to two dimensions. The color of each point in the map corresponds to each loadshape. The grouping of similar loadshapes shows how the cluster methods produce similar results.
from sklearn.manifold import TSNE
import matplotlib.colors
import numpy as np
tsne = TSNE()
results_tsne = tsne.fit_transform(rescaled)
color_list = list(zip(np.arange(0,1,0.1),np.arange(0,1,0.1),np.arange(1,0,-0.1)))
cmap = matplotlib.colors.LinearSegmentedColormap.from_list(groups.index.get_level_values(level=1).unique(), color_list)
plt.figure(figsize=(10,10))
plt.scatter(results_tsne[:,0], results_tsne[:,1],
c=groups.index.get_level_values(level=1),
cmap=cmap,
alpha=0.6,
);
This provides an simple example from which most analysts and researchers can develop their own loadshapes from AMI data. In some cases it may be necessary to do some preprocessing to the AMI data to normalize timestamps, aggregate subhourly data up to hourly day, or removed extraneous columns. These tasks are relatively simple and straightforward, and are common enough that the reader should have no problem implementing these for themselves.